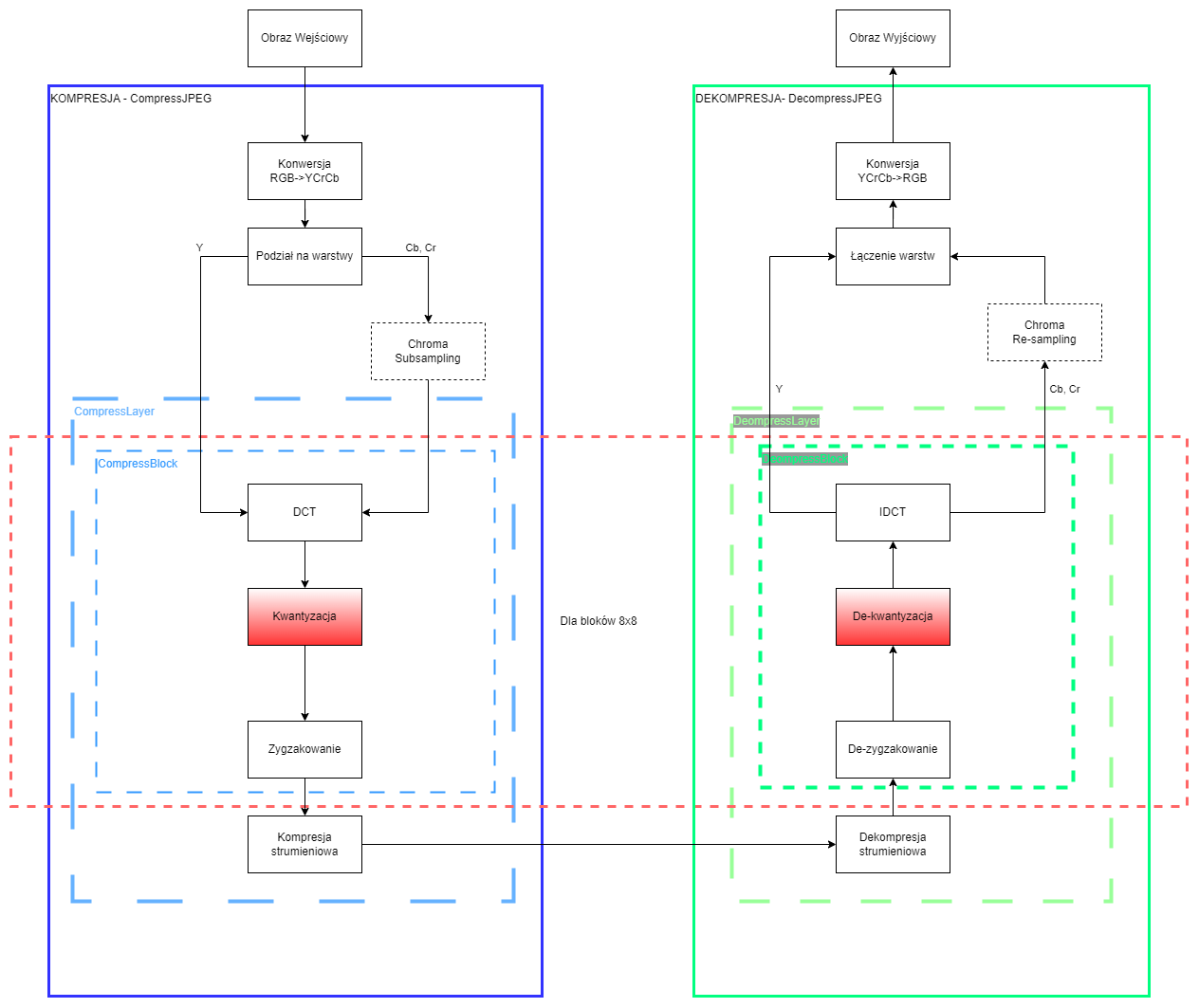
JPEG (ang. Joint Photographic Experts Group) to algorytm stratnej kompresji grafiki rastrowej, wykorzystany w formacie plików graficznych o tej samej nazwie. Istnieje kilka sporo modyfikacji algorytmu JPEG, ale głównie używany algorytm kompresji JPEG można przedstawić za pomocą kilku kroków:
- Konwersja z przestrzeni
RGBdo przestrzeniYCbCr(luminancja i dwie warstwy chrominancji) - Ewentualna redukcja chrominancji (Chroma Subsampling)
- Podział obrazu na bloki 8x8 (każda warstwa przetwarzana jest osobno)
- Wykonanie dyskretnej transformaty kosinusowej (DCT)
- Kwantyzacja poprzez zastąpienie wartości zmiennoprzecinkowych, wartościami całkowitymi.
- Ewentualne dzielenie przez macierze kwantyzacji w celu zwiększenia kompresji
- Porządkowanie współczynników DCT w sposób liniowy poprzez zygzakowanie
- Kompresja bezstratna danych najczęściej algorytmem Hoffmanna.
Zainteresowanych matematyką, jaka stoi za całym algorytmem i sposobem ich wyliczania, odsyłam do obejrzenia dwóch filmów na YouTube temu poświęconym, które dobrze to prezentują Część 1 [ENG] oraz Część 2 [ENG].
Nasz algorytm
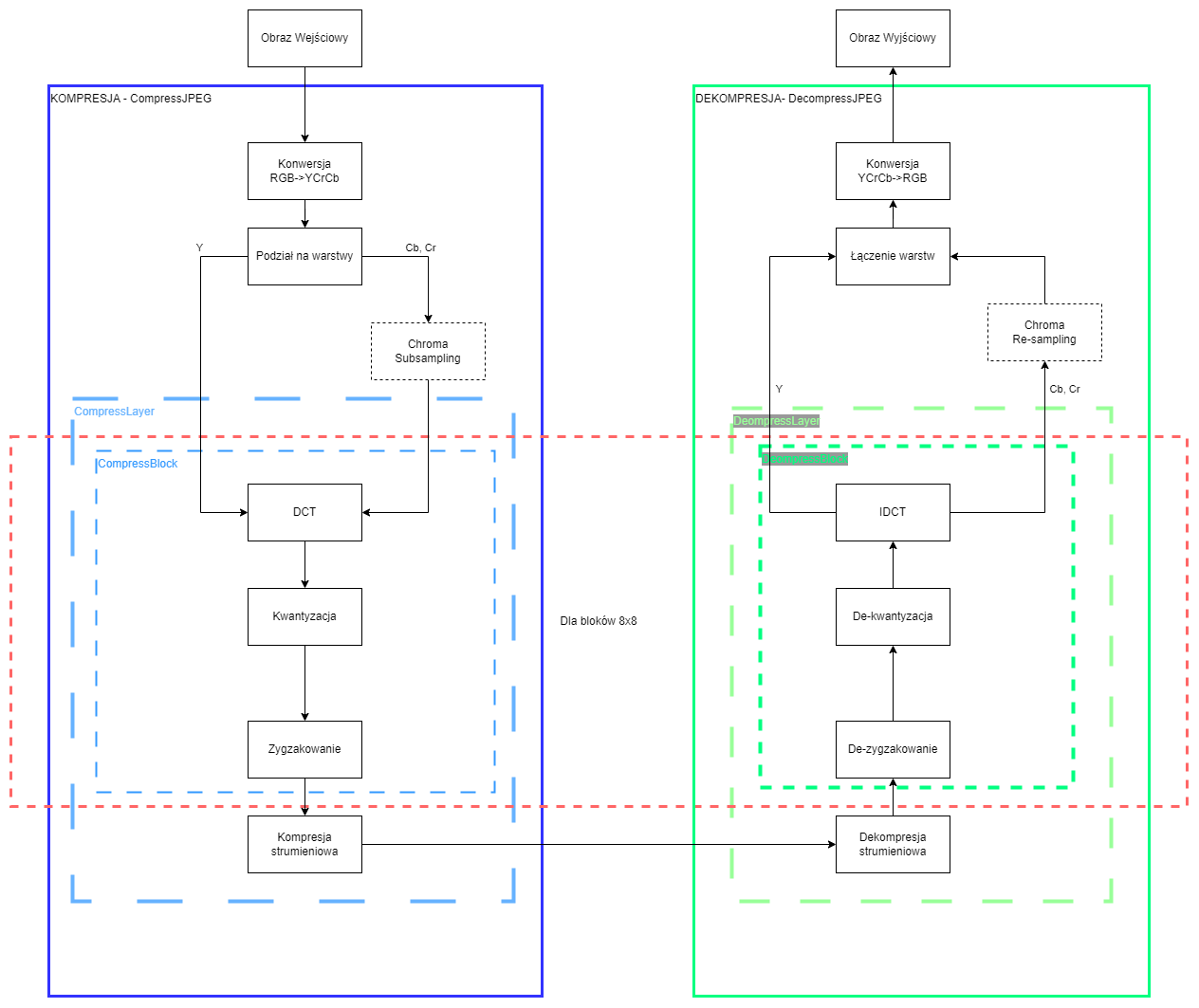
Pisany przez nas algorytm będzie finalnie przebiegał według powyższego schematu, ale będziemy go powoli rozwijać, monitorując efekty jego działania. Każdemu z etapów działania algorytmu kompresji odpowiada funkcja odwrotna wykorzystywana na tym samym etapie podczas dekompresji. Dlatego na każdym etapie będziemy implementować od razu obie funkcjonalności jednocześnie i sprawdzać ich działanie. Do przechowywania skompresowanej informacji o naszej kompresji najlepiej wykorzystać pustą klasę lub klasę z już zadeklarowanymi elementami, ale proszę nie umieszczać w niej żadnych dodatkowych funkcji:
## wybrać jeden kontener i nie umieszczać w nim dodatkowych funkcji
class ver1:
Y=np.array([])
Cb=np.array([])
Cr=np.array([])
ChromaRatio="4:4:4"
QY=np.ones((8,8))
QC=np.ones((8,8))
shape=(0,0,3)
class ver2:
def __init__(self,Y,Cb,Cr,OGShape,Ratio="4:4:4",QY=np.ones((8,8)),QC=np.ones((8,8))):
self.shape = OGShape
self.Y=Y
self.Cb=Cb
self.Cr=Cr
self.ChromaRatio=Ratio
self.QY=QY
self.QC=QCW obu przypadkach będziemy odwoływać się do elementów w jej wnętrzu w ten sam sposób:
data1=ver1()
data1.shape=(1,1)
data2=ver2(...)
data2.shape=(1,1)Pracując z naszym algorytmem, zakładamy, że wymiary naszego obrazu są podzielne przez \(8\) (lub najlepiej \(16\)), w przeciwnym przypadku musimy uzupełnić brakujące piksele (innymi wartościami).
Uwaga: Jeżeli natraficie na jakieś problemy, coś nie będzie się dobrze wyświetlać lub nie będziecie wiedzieć, jak coś zrobić radzę sprawdzić sekcję z uwagami końcowymi w instrukcji, gdzie prawdopodobnie będą znajdować się informacje na ten temat.
Przestrzeń YCbCr
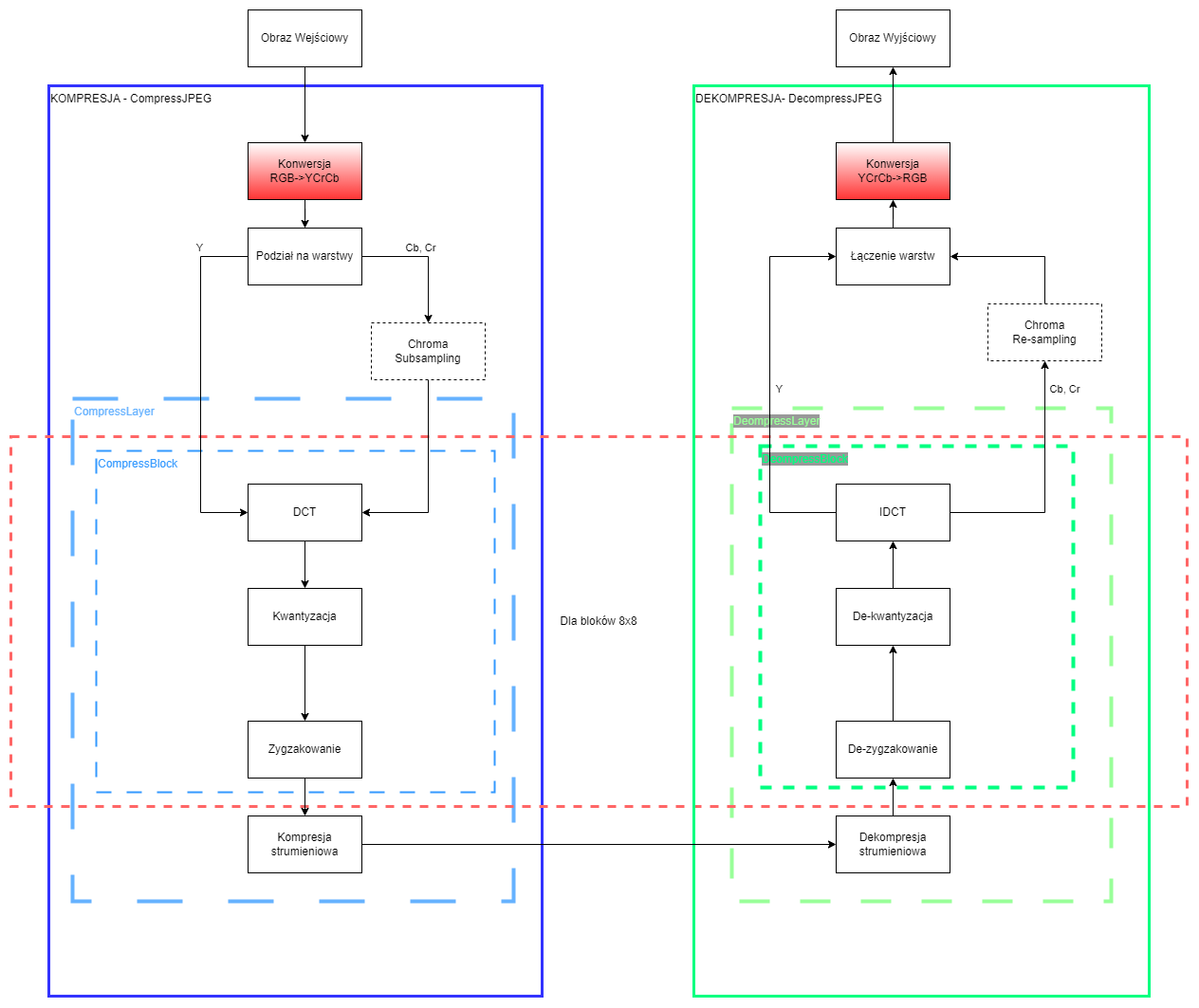
Na początku musimy zmienić nasza przestrzeń koloru, w jakiej reprezentowany jest nasz obraz. Wykorzystamy do tego przestrzeń YCbCr (UWAGA! W OpenCV generowaną jako YCrCb). Jest to model przestrzeni kolorów używany do cyfrowego przesyłania oraz przechowywania obrazów i wideo. Wykorzystuje do tego trzy typy danych: Y – składową luminancji, Cb – składową różnicową chrominancji Y-B, stanowiącą różnicę między luminancją a niebieskim, oraz Cr – składową chrominancji Y-R, stanowiącą różnicę między luminancją a czerwonym. Kolor zielony jest uzyskiwany na podstawie tych trzech wartości. Do przejścia pomiędzy tymi przestrzeniami wykorzystamy OpenCV. Pamiętać należy jednak, że domyślnie obraz dla OpenCV jest zapisany albo w typie uint8 (lub float, ale dzisiaj tego nie będziemy tego używać), jednak pozostanie na tym typie danych, znacząco utrudni nam wykonywanie dalszych operacji, dlatego pamiętać o wykonywaniu odpowiednich rzutowań.
YCrCb=cv2.cvtColor(RGB,cv2.COLOR_RGB2YCrCb).astype(int)
RGB=cv2.cvtColor(YCrCb.astype(np.uint8),cv2.COLOR_YCrCb2RGB)Uwaga: Dyskretna transformacja cosinusowa (DCT) powinna otrzymywać dane wyśrodkowane na 0. Obrazy na uint8 są wyśrodkowane na wartości 128, dlatego przed operacją należy od wartości każdej warstwy należy odjąć wartość 128 przed prowadzeniem obliczeń (można robić to na całym obrazie lub wewnątrz funkcji kompresującej blok) oraz dodać tę wartość po odtworzeniu.
Konstrukcja programu
W ramach programu powinny znaleźć się dwie funkcje kompresji i dekompresji. Funkcja kompresji powinna przyjąć jako argument wszystkie informacje, jakie potrzebujemy do działania naszego algorytmu, a następnie zwrócić klasę z tymi informacjami w taki sposób, żeby funkcja dekompresji była w stanie je odtworzyć. Może być to coś podobnego do poniższych przykładów.
def CompressJPEG(RGB,Ratio="4:4:4",QY=np.ones((8,8)),QC=np.ones((8,8))):
# RGB -> YCrCb
JPEG= verX(...)
# zapisać dane z wejścia do klasy
# Tu chroma subsampling
JPEG.Y=CompressLayer(JPEG.Y,JPEG.QY)
JPEG.Cr=CompressLayer(JPEG.Cr,JPEG.QC)
JPEG.Cb=CompressLayer(JPEG.Cb,JPEG.QC)
# tu dochodzi kompresja bezstratna
return JPEG
def DecompressJPEG(JPEG):
# dekompresja bezstratna
Y=DecompressLayer(JPEG.Y,JPEG.QY)
Cr=DecompressLayer(JPEG.Cr,JPEG.QC)
Cb=DecompressLayer(JPEG.Cb,JPEG.QC)
# Tu chroma resampling
# tu rekonstrukcja obrazu
# YCrCb -> RGB
return RGBPodział na bloki i rekonstrukcja danych
Pomińmy na moment etap redukcji chrominancji (omówimy go szczegółowo pod koniec instrukcji) i przejdźmy do operacji wykonywanych na samych blokach 8x8. Warto wyodrębnić zestaw operacji wykonywanych na blokach jako osobną funkcję, ponieważ same operacje są niezależne od warstwy, na której będzie wykonywana operacja oraz ewentualnymi dodatkowymi parametrami, które będziemy do niej przekazywać. Nie próbujcie też wykonywać wszystkich operacji na wszystkich trzech warstwach na raz. Przetwarzajcie każdą warstwę osobno. Funkcja kodująca będzie przyjmować tablicę dwuwymiarową (8x8) i po całej operacji będzie zwracać wektor 64-elementowy. Funkcja dekodująca natomiast będzie przyjmować ten wektor i zwróci tablicę (8x8). Poniżej przykład:
def CompressBlock(block,Q):
###
return vector
def DecompressBlock(vector,Q):
###
return blockSamo wyodrębnienie naszych bloków podczas kodowania wykonać można poprzez użycie podwójnej pętli for po kolumnach i wierszach z krokiem 8. Natomiast przy rekonstrukcji można wykorzystać indeks (idx w kodzie poniżej) do wyliczenia pozycji bloku w przestrzeni przy użyciu prostych operacji arytmetycznych (% oraz //) i informacji jak szeroki jest nasz obraz.
## podział na bloki
# L - warstwa kompresowana
# S - wektor wyjściowy
def CompressLayer(L,Q):
S=np.array([])
for w in range(0,L.shape[0],8):
for k in range(0,L.shape[1],8):
block=L[w:(w+8),k:(k+8)]
S=np.append(S, CompressBlock(block,Q))
## wyodrębnianie bloków z wektora
# L - warstwa o oczekiwanym rozmiarze
# S - długi wektor zawierający skompresowane dane
def DecompressLayer(S,Q):
L= # zadeklaruj odpowiedniego rozmiaru macierzy
for idx,i in enumerate(range(0,S.shape[0],64)):
vector=S[i:(i+64)]
m=L.shape[1]/8
k=int((idx%m)*8)
w=int((idx//m)*8)
L[w:(w+8),k:(k+8)]=DecompressBlock(vector,Q)Operacje wykonywane na blokach — część 1
Jak było już wspomniane podczas podziału na bloki, operacje zamieszczone, w tej części instrukcji warto umieszczać wewnątrz funkcji, która będzie przetwarzać całe bloki. Operacje wykonywane na różnych warstwach różnią się tylko parametrami (inna macierz Q), a nie operacjami. Na tym etapie nasza funkcja będzie zawierała tylko diw poniższe operacja.
Dyskretna transformacja cosinusowa (DCT)
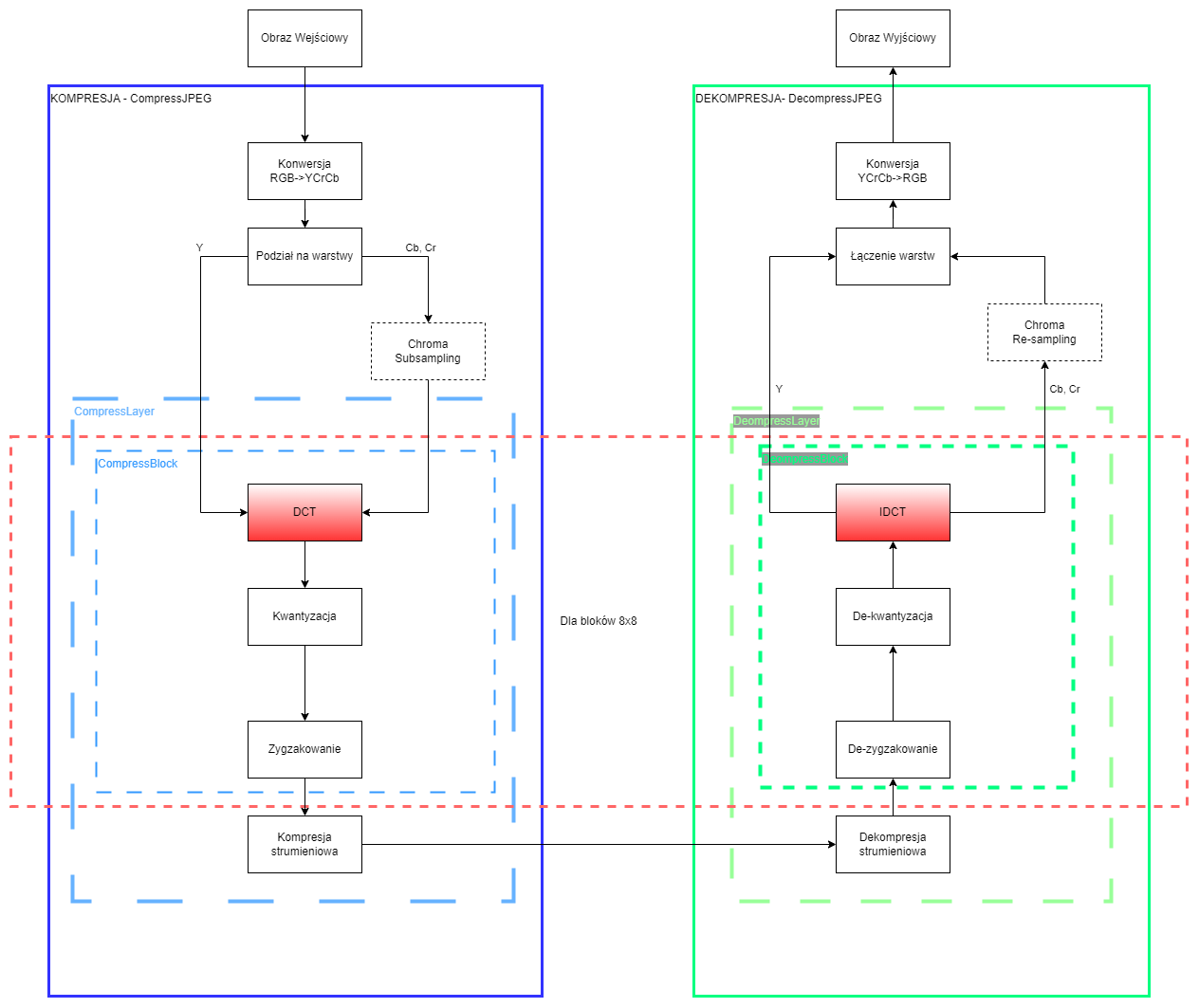
Pierwszym etapem kompresji na naszym bloku danych jest wyliczenie współczynników dla dyskretnej transformacji cosinusowej (DCT). Poniżej znajduje się kod funkcji realizującej dwuwymiarowe DCT, jak również jej odwrotność IDCT2. Obie funkcje zwracają macierze 8x8 zawierające liczby zmiennoprzecinkowe (float). Dla osób zainteresowanych zrozumieniem jak działa DCT odsyłam, do wcześniej załączonych filmów oraz literatury. Ogólnie służy ona do wyznaczenia współczynników DCT, czyli jak dużo składowych cosinusowych, o określonych okresach należy dodać do siebie, aby otrzymać nasz sygnał źródłowy. W punkcie (0,0) naszej macierzy (podobnie jak w widmie Fourierowskim) znajduje się składowa stała, a im dalej on niego znajdują się składowe o wyższych częstotliwościach.
import scipy.fftpack
def dct2(a):
return scipy.fftpack.dct( scipy.fftpack.dct( a.astype(float), axis=0, norm='ortho' ), axis=1, norm='ortho' )
def idct2(a):
return scipy.fftpack.idct( scipy.fftpack.idct( a.astype(float), axis=0 , norm='ortho'), axis=1 , norm='ortho')Zygzakowanie
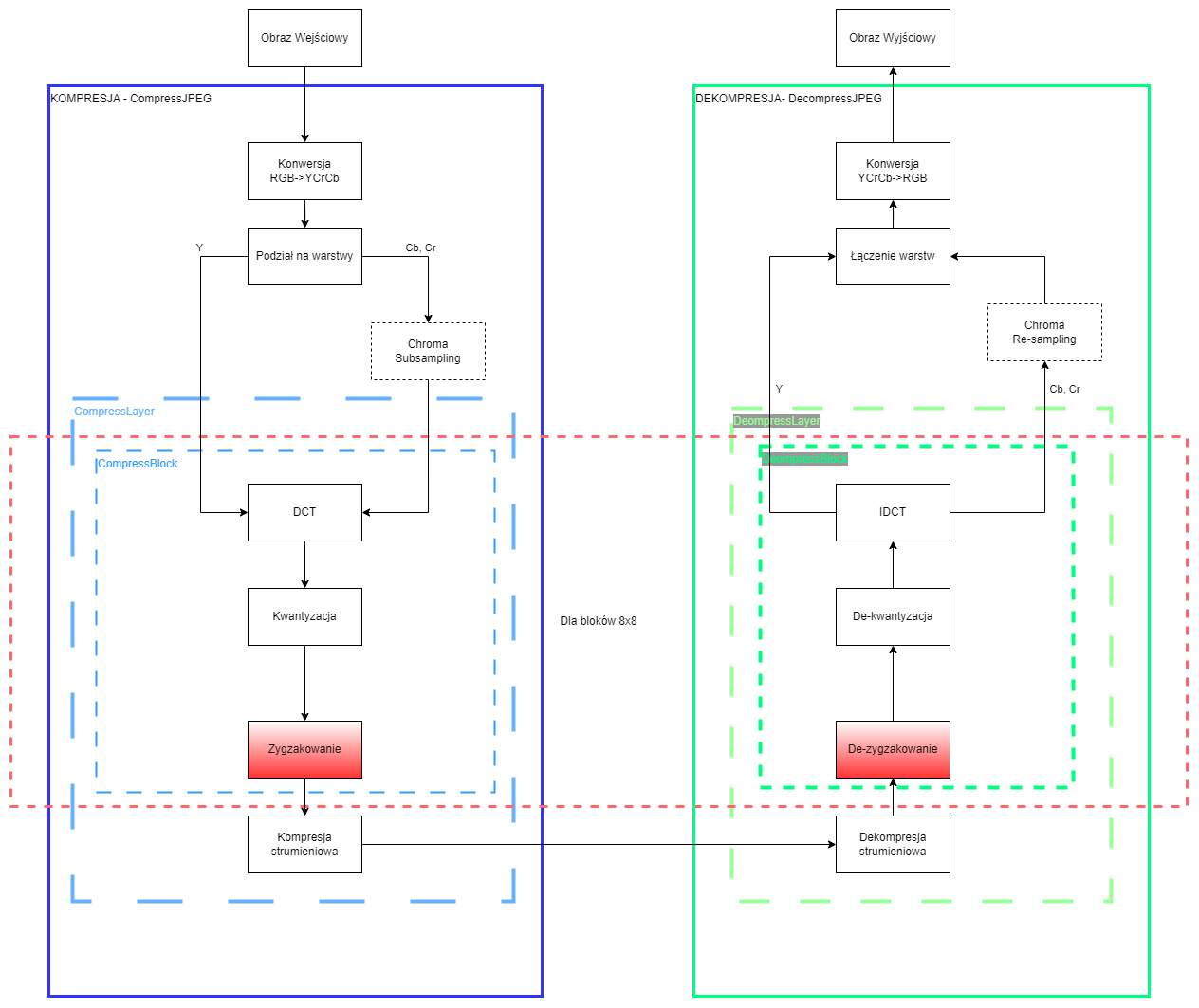
Na chwilę pomijamy kolejny krok, żeby zaimplementować ostatnią funkcję niepowodującą utraty, żadnych danych. Funkcja zygzakująca (ang. ‘zigzagging’) zamienia ona macierz 8x8 na wektor 64-elementowy, ale w przeciwieństwie do funkcji .flatten(), robi to według poniższego schematu:
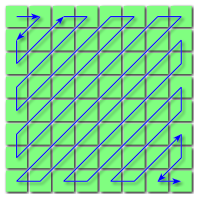
Taka operacja przydaje się bardzo przy porządkowaniu danych przed dalszą kompresją. W wyniku kwantyzacji danych będziemy posiadali zwykle bardzo dużo zer w wyższych partiach częstotliwości, które przy takim zgrupowaniu, powinny tworzyć dłuższe ich ciągi, ułatwiając ich kompresję.
def zigzag(A):
template= np.array([
[0, 1, 5, 6, 14, 15, 27, 28],
[2, 4, 7, 13, 16, 26, 29, 42],
[3, 8, 12, 17, 25, 30, 41, 43],
[9, 11, 18, 24, 31, 40, 44, 53],
[10, 19, 23, 32, 39, 45, 52, 54],
[20, 22, 33, 38, 46, 51, 55, 60],
[21, 34, 37, 47, 50, 56, 59, 61],
[35, 36, 48, 49, 57, 58, 62, 63],
])
if len(A.shape)==1:
B=np.zeros((8,8))
for r in range(0,8):
for c in range(0,8):
B[r,c]=A[template[r,c]]
else:
B=np.zeros((64,))
for r in range(0,8):
for c in range(0,8):
B[template[r,c]]=A[r,c]
return BDo tego momentu wszystkie operacje są odwracalne, czyli nie powodują utraty informacji. Wszystkie dalsze operacje powodują już pewną utratę informacji. Na tym etapie warto sprawdzić, czy was kod działa poprawnie i czy odtwarza wasz obraz.
Operacje wykonywane na blokach — część 2
Teraz przejdziemy do dodawania operacji, które powodują już utratę informacji.
Kwantyzacja
Wróćmy teraz do naszych współczynników DCT, podstawową formą ich kwantyzacji jest zwykła zmiana z formatu zmiennoprzecinkowego na liczby całkowite (.astype(int)). Powoduje to pewną utratę informacji, ale jest ona stosunkowo niewielka. Drugim sposobem na zaoszczędzenie pamięci, jest zmniejszenie wpływu komponentów DCT o większych częstotliwościach na nasz rekonstruowany obraz, poprzez podzielenie wszystkich wartości dla komponentów DCT przez tzw. tablice kwantyzacji. Poniżej podano dwie takie tablice pochodzące ze standardu JPEG dla jakości 50%. Pierwsza z nich jest przeznaczona do kompresji Luminancji (Y) druga dla Chrominancji (Cb oraz Cr). Podczas kwantyzacji dzielimy naszą macierz współczynników DCT przez naszą tablicę, a podczas de-kwantyzacji mnożymy je przed poddaniem ich działaniu IDCT. Do otrzymania pierwszej wersji naszej kwantyzacji, czyli prostego rzutowania na int możemy zastąpić naszą macierz Q wartościami \(1\). Ponieważ \(1\) jest elementem neutralnym, wiec dzielenie i mnożenie przez niego da nam te same wartości.
qd=np.round(d/Q).astype(int)
pd=qd*QOperacja ta spowoduje, że w ciągu poddanym zygzakowaniu pojawi się znacznie więcej zer, co ułatwi jego dalszą kompresję. Tablicę kwantyzacji do naszej funkcji przetwarzającej bloki jako parametr, ponieważ różne warstwy wykorzystują różne tablice kwantyzacji. Należy również pamiętać, że wykorzystywaną tablicę należy dołączyć do naszej struktur, ponieważ jest ona również potrzebna do dekompresowania obrazu.
Tablica Kwantyzacji dla Luminancji dla jakości 50%:
QY= np.array([
[16, 11, 10, 16, 24, 40, 51, 61],
[12, 12, 14, 19, 26, 58, 60, 55],
[14, 13, 16, 24, 40, 57, 69, 56],
[14, 17, 22, 29, 51, 87, 80, 62],
[18, 22, 37, 56, 68, 109, 103, 77],
[24, 36, 55, 64, 81, 104, 113, 92],
[49, 64, 78, 87, 103, 121, 120, 101],
[72, 92, 95, 98, 112, 100, 103, 99],
])Tablica kwantyzacji dla Chrominancji po redukcji 2:1 dla jakości 50%, ale można ją stosować również na pełnej chrominancji:
QC= np.array([
[17, 18, 24, 47, 99, 99, 99, 99],
[18, 21, 26, 66, 99, 99, 99, 99],
[24, 26, 56, 99, 99, 99, 99, 99],
[47, 66, 99, 99, 99, 99, 99, 99],
[99, 99, 99, 99, 99, 99, 99, 99],
[99, 99, 99, 99, 99, 99, 99, 99],
[99, 99, 99, 99, 99, 99, 99, 99],
[99, 99, 99, 99, 99, 99, 99, 99],
])Tablica neutralna dla zwykłego rzutowania na int:
QN= np.ones((8,8))Redukcja Chrominancji — Chroma Subsampling
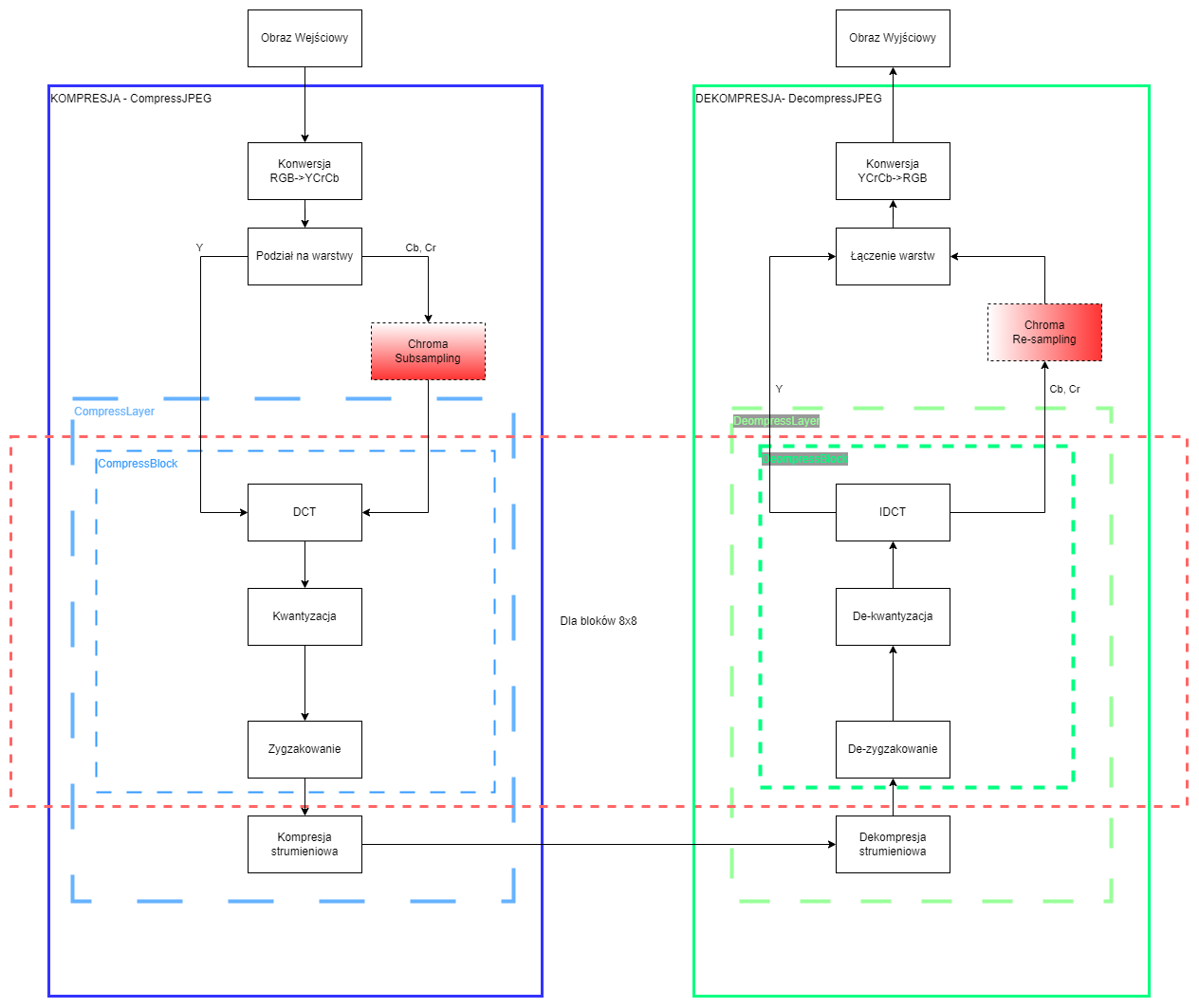
Kolejnym wcześniej przez nas wcześniej etapem jest redukcja chrominancji (ang. Chroma Subsampling). Jest to jedna z operacji kompresji polegająca na zmniejszeniu informacji na temat koloru w naszym obrazie. Wykorzystujemy tutaj fakt, że ludzkie oko jest bardziej wrażliwe na zmianę jasności (Luminancja), niż koloru (Chrominancja). Subsampling zatem wykonujemy na warstwach Cb oraz Cr (dla każdej z nich osobno). Jego rodzaj opisywany jest przez 3 wartości opisane w ciągu J:a:b. W przypadku naszego algorytmu JPEG będziemy zajmować się tylko dwoma aspektami redukcji chrominancji. Są to wersje: 4:4:4 oraz 4:2:2. Poniżej trochę więcej informacji na ten temat, wraz z przykładami.
Kompresja bezstratna?
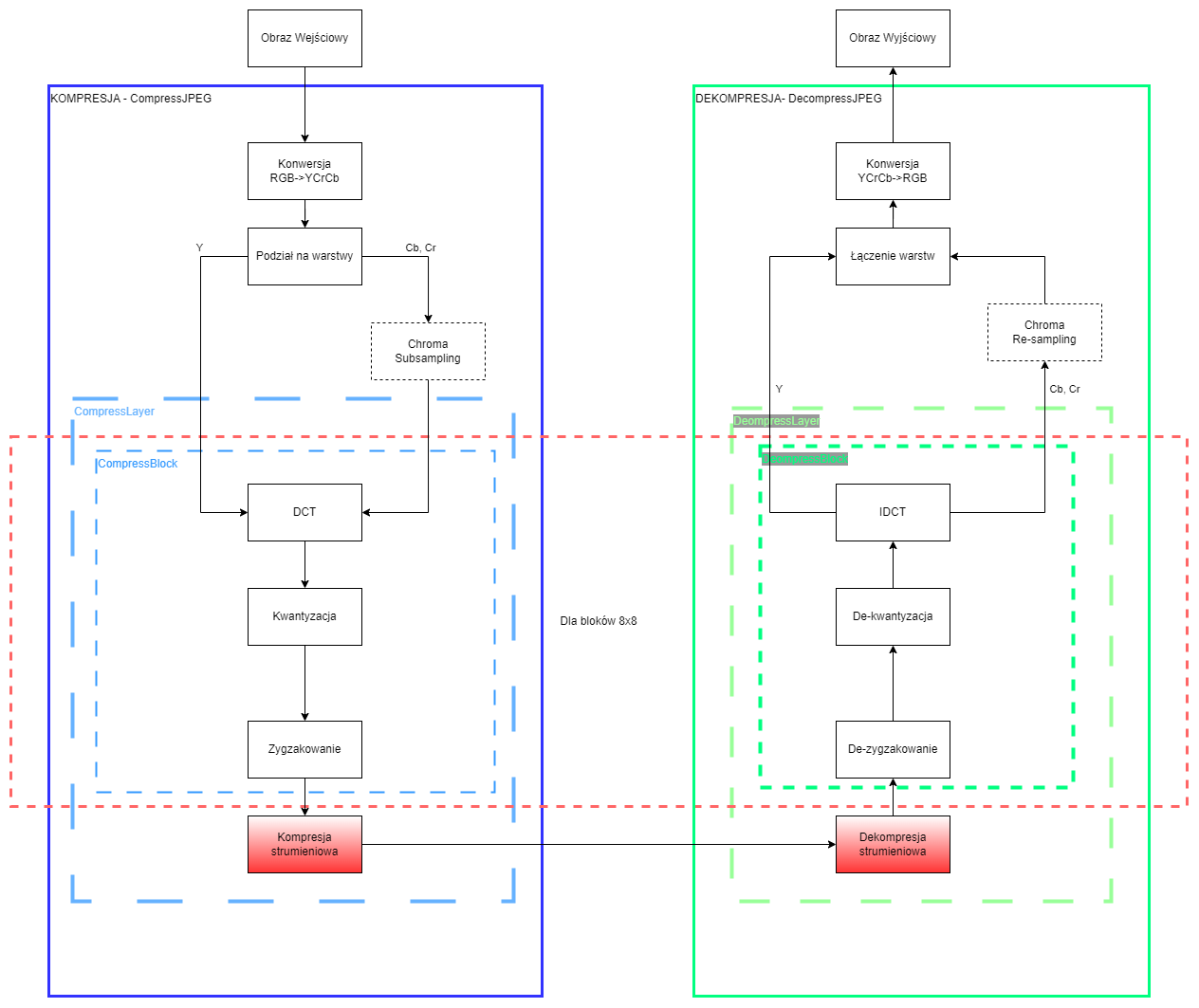
W standardzie JPEG wykorzystywane jest najczęściej kodowanie algorytmem Hoffmanna i w nagłówku zapisywana jest cały słownik służący do dekompresji. W naszym przypadku wykorzystamy zamiast tego napisany w ramach jednych z poprzednich algorytm RLE lub ByteRun. Głównie w celu sprawdzenia o ile skrócą się nasze wektory zawierające poszczególne warstwy obrazu.
Podsumowanie
Gotowy algorytm powinien działać w miarę poprawnie. Ewentualne problemy i sposoby ich rozwiązania zostały zawarte w uwagach końcowych (jeżeli będą dalsze problemy, rozwiązania będą się pojawiać w tej sekcji). Efekty przy niewielkiej kompresji powinny wyglądać mniej więcej tak na poniższym obrazie:

Uwagi Końcowe
Jak złożyć 3 osobne warstwy w jeden obraz?
YCrCb=np.dstack([Y,Cr,Cb]).clip(0,255).astype(np.uint8)Jak najlepiej wyświetlać obrazy podczas testów?
Rozwiązanie dla niewielkich obszarów do testów w przypadku większych fragmentów wyświetlany obraz może być za miały i nieczytelny. Polecam uzupełnić poniższy fragment o brakujące fragmenty kodu oraz odpowiednie etykiety i nagłówki. Następnie przerobić go na funkcję przyjmującą dwa obrazy w RGB (przed i po kompresji).
fig, axs = plt.subplots(4, 2 , sharey=True ) fig.set_size_inches(9,13) # obraz oryginalny axs[0,0].imshow(PRZED_RGB) #RGB PRZED_YCrCb=cv2.cvtColor(PRZED_RGB,cv2.COLOR_RGB2YCrCb) axs[1,0].imshow(PRZED_YCrCb[:,:,0],cmap=plt.cm.gray) axs[2,0].imshow(PRZED_YCrCb[:,:,1],cmap=plt.cm.gray) axs[3,0].imshow(PRZED_YCrCb[:,:,2],cmap=plt.cm.gray) # obraz po dekompresji axs[0,1].imshow(PO_RGB) #RGB PO_YCrCb=cv2.cvtColor(PO_RGB,cv2.COLOR_RGB2YCrCb) axs[1,1].imshow(PO_YCrCb[:,:,0],cmap=plt.cm.gray) axs[2,1].imshow(PO_YCrCb[:,:,1],cmap=plt.cm.gray) axs[3,1].imshow(PO_YCrCb[:,:,2],cmap=plt.cm.gray)Obraz po dekompresji wygląda na szary, mimo że wyświetlone osobno warstwy wyglądają dobrze?
Nasz algorytm nie jest doskonałym, więc pewnie zdarzy się, że odtworzony po dużej kwantyzacji obraz będzie miał dużo mniejszą dynamikę kolorów niż oryginał. Dlatego trzeba wykorzystać małą sztuczkę do obejścia tego problemu. Zapisujemy wewnątrz naszej skompresowanej struktury zakres wartości dla poszczególnych warstw (minimum i maksimum). A potem przed scaleniem każdej warstwy przywracamy ten zakres.